8
Key Results
Edge recovery at threshold τ = 0.68
Precision
0.89
Recall
1.00
F1 Score
0.94
Edge Count Comparison
Complete graph 45 edges
Ground truth 8 edges
Pruned (τ=0.68) 9 edges
Reduction 80%
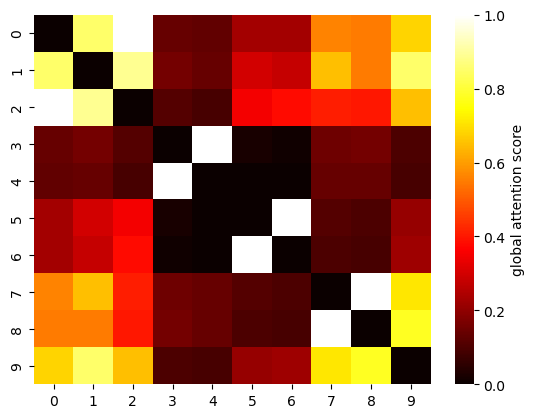
Global attention score heatmap (MF matrix)
| Model | MAE |
|---|---|
| Null (no edges) | 0.397 |
| Complete (45 edges) | 0.088 |
| Pruned (9 edges) | 0.072 |
| Oracle (8 edges) | 0.070 |
18% lower MAE than complete graph
Ablation: Partial Interaction Groups (avg MAE, 10 runs)
$$y = \frac{1}{1+x_{0}^{2}+x_{1}^{2}+x_{2}^{2}} + \sqrt{\exp{(x_3+x_4)}} + |x₅+x₆| + x₇x₈x₉$$
| Included groups | MAE |
|---|---|
| {x₃,x₄}, {x₅,x₆}, {x₇,x₈,x₉} | 0.079 |
| {x₀,x₁,x₂}, {x₃,x₄}, {x₇,x₈,x₉} | 0.091 |
| {x₅,x₆}, {x₇,x₈,x₉} | 0.101 |
| {x₀,x₁,x₂}, {x₇,x₈,x₉} | 0.117 |
| {x₀,x₁,x₂}, {x₃,x₄}, {x₅,x₆} | 0.155 |